
运行方式
交互式解析器
命令行脚本
集成开发环境
Pip
1 | pip install package |
Requests
- 发起请求
- 获取请求返回状态码
- 获取请求返回头部信息
- 获取请求返回内容
BeautifulSoup
解析 HTML、XML 文档、修复含有未闭合标签等错误的文档,为待解析的页面建立一棵树,以便提取其中的数据。
Scrapy
Scrapy 是快速高级的 web 爬虫框架,用于抓取网站并从网页中提取结构化数据。
优势
- HTML, XML 源数据 选择及提取 的内置支持
- 通过 feed 导出 提供了多格式(JSON、CSV、XML),多存储后端(FTP、S3、本地文件系统)的内置支持
提供了 media pipeline,可以 自动下载 爬取到的数据中的图片(或者其他资源)。 - 内置的中间件及扩展为下列功能提供了支持:
cookies and session 处理
HTTP 压缩
HTTP 认证
HTTP 缓存
运行环境
- Python 2.7 or Python 3.4+
- Works on Linux, Windows, Mac OSX, BSD
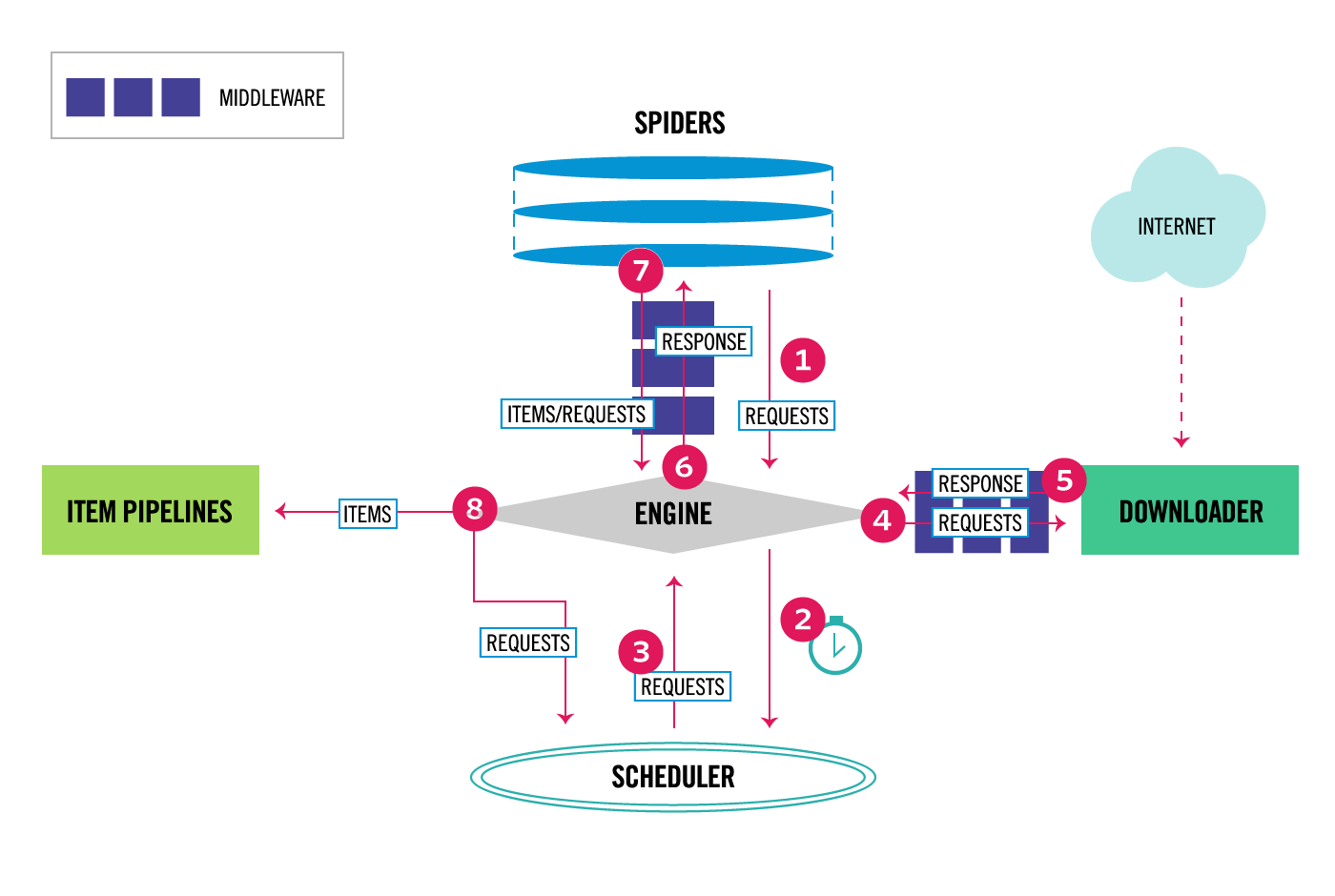
核心组件
Spider
用户定义爬取动作、分析爬取数据的地方
name: 定义 spider 名字,必须是唯一的start_urls:指定了一组 URLs 告诉 spider 从什么地方开始去进行爬取parse:当 response 没有指定回调函数时,该方法是 Scrapy 处理下载的 response 的默认方法Item
Item对象是中简单的容器,保存爬取得到的数据。提供了类似词典的api用于声明可用字段的简单语法
Pipelines
接收从 spider 中返回的 Item,通过 pipeline 的各个组件决定是否继续处理数据还是丢弃数据不再处理。主要功能如下:- 清理数据
- 验证数据
- 数据查重
- 数据储存
Middlewares
Downloader middlewares(下载中件): 在网页在下载前、后进行逻辑处理
Spider middlewares(爬虫中件):调用爬虫输入下载结果和输出请求/数据时进行逻辑处理
Scrapy Engine(引擎)
核心引擎,负责控制和调度各个组件,保证数据流转
Scheduler(调度器)
负责管理任务、过滤任务、输出任务的调度器,存储、去重任务都在此控制;
Downloader
载器,负责在网络上下载网页数据,输入待下载URL,输出下载结果
Pyspider
自带WebUI的界面, 配置灵活性没Scrapy高。